
An article I wrote for a risk management class. As I get further through my MBA I think I’ll post more of my writing here for anyone who’s interested.
What are algorithms?
Algorithms are becoming increasingly ubiquitous in our everyday lives. Whether at home or work, we use them every day, sometimes without even noticing. An algorithm can be defined as a process or sequence of rules for analyzing data, problem-solving or carrying out a task[1]. In the past, algorithms would be programmed manually to perform a specific task, but with the advancement of technology, including Moore’s Law, big data, and The Cloud, algorithms can now perform numerous tasks on their own1. Feeding a computer large data sets to improve algorithmic performance is known as machine learning (ML), a branch of artificial intelligence (AI) [2]. This new ability allows computers to independently perform tasks as well as—and, in many instances, even better than—humans. The implications of this new automated technology have been massive for organizations. Machine learning has opened a pandora’s box for businesses looking to gain a competitive advantage in this increasingly digital landscape. However, with new business applications come new organizational risks to consider. There have been many high-profile examples in recent years of algorithms running amuck, including the role they played in swaying public opinion during the 2016 U.S. presidential election[3]. Machine learning was also the root cause of a self-driving Uber that killed a pedestrian because the car failed to recognize she was jaywalking[4]. Further, algorithms were accused of causing the “flash crash” of the British pound in 2016[5]. Before businesses can mitigate these risks, they must identify them and the sources that create these issues.
Implications for risk, strategy, and strategic risk
Understanding algorithmic risks

The fundamental risk in using algorithms is that they lead to a decision, whether automatic or human-made, that can hurt the organization. As algorithms grow in complexity, many end users have compared them to black boxes; an opaque tool that yields an output without ever truly knowing how it achieved that result5. These machine learning models are indeed more complex than traditional statistical models, primarily because they operate on a much larger data set. However, the approach to understanding algorithmic risk still follows the same principles as regular mathematical models. Figure 1 from Deloitte’s 2017 report on ML risk has identified three areas exposed to algorithmic risks and the underlying factors that can create these issues7. Many of these elements are issues paramount to traditional models, as well; however, the difference with machine learning is that these underlying factors are immensely amplified and, therefore, the consequences are also increased.
Input data risk can be defined by the expression “garbage in, garbage out.” With machine learning, poor inputs can be magnified to produce large-scale problems. Human bias commonly affects inputs and can lead to demographic segregation or unequal opportunities within the model[6]. AI can also have biases. Machine learning models use large unstructured data sets with multiple types of inputs and certain algorithms may favour one kind of input over another6.
Selecting the right algorithm for the task also ties into design risk. Design risks stem from a lack of diligence around selecting, developing, and testing the algorithms being used within the organization[7]. Poor governance of design can lead to inappropriate model selection, bugs, and inaccurate outputs.
Output decision risks are centred around interpretability and the inappropriate use of results7. Human error and a lack of understanding around the assumptions and inputs can lead to the incorrect use of the outputs. A lack of comprehension can also lead decision-makers not to trust the results and ignore them.
Input, design, and output are all subject to security flaws and can be exploited to yield perverse results. For example, hackers can manipulate the data used as inputs to produce an outcome that benefits them7.
Impact on strategy
AI is quickly becoming widely accepted within many industries. Banking has seen an explosion in the use of algorithms, from assisting customers to executing trades6. Imbedding AI into your business strategy can provide a source of competitive advantage over competitors that are slow to adapt. Unfortunately, numerous firms are struggling with adoption and are failing to create new value with this technology[8]. Difficulties with strategic alignment due to a fast-moving digital landscape could be one reason for this breakdown8. Some companies see AI as a passing opportunity to improve minor aspects of their operation in a continually changing technology market. And these uses of AI should not be understated. Many organizations are benefiting from algorithms at a small scale, improving efficiencies and reducing costs8.
On the other hand, real gains are being achieved by companies that are fully incorporating machine learning into their strategy and using it to generate revenue8. They are moving away from outsourcing and are hiring internal talent to champion this technology within their organizations8. Change initiatives can take time, and the companies committed in the long-term will see the most reward.
The main barrier impeding companies from committing to these large transformational initiatives is that they carry greater strategic risk.
Impact on strategic risk
As algorithms begin to play a more significant role in a company’s strategy, the strategic risks they create increase as well. Using Slywotsky and Drzik’s taxonomy of strategic risk, these issues can be grouped into the following categories[9].
Brand risk
Algorithms can expose the organization to reputational risk that can potentially damage the company’s brand7. The example above of Uber and the autonomous vehicle is an example of this risk. Output errors can lead to business decisions that are not in line with external stakeholders’ expectations. If these errors paint the firm in a negative light, a company’s goodwill may be impaired, and customers may switch to a competitor.
Project/operational risk
A fully integrated approach to machine learning can have a significant impact on operational and financial risk. Using algorithms to assist with finance and accounting can lead to financial losses when there are errors in the outputs. Furthermore, algorithmic problems in machine learning models used to automate aspects of production and supply chain can bring operations to a standstill[10].
Technology risk
Cybersecurity is a massive risk for any new technology adoption. Hackers can exploit the same patterns that ML algorithms use to generate outputs for their own purposes[11]. The example mentioned earlier regarding the manipulation of input data was one such case of pattern identification. Other algorithm-based technology, such as biometric systems, can be altered to gain access to user profiles11. Furthermore, algorithms, like all technologies that interface with the web, create broader vulnerabilities for a company’s information technology infrastructure.
Industry (regulatory) risk
Adopting machine learning models in business strategy opens the firm up to two different types of regulatory risk. Internal risk occurs when automated decision making unknowingly breaches specific laws and regulations10. If the parameters given to an algorithm are not appropriately defined, the system may achieve its goal while creating legal issues in the process.
Externally, increased regulatory pressure on the use of algorithms could hamper a company’s strategy. The current regulatory environment for algorithms is relatively lax10. An organization could build its strategy on the back of AI, only to have their competitive advantage reduced when lawmakers catch up to the technology.
Customer risk
As previously mentioned, cognitive biases can find their way into algorithms and manifest themselves in outputs. Machine learning techniques applied to sales and marketing can lead to unfair price discrimination based on customer demographics10. For example, in banking, automated credit checks may not approve certain customers for credit based on inappropriate interpretation of data[12]. In healthcare, patients may be denied medical services based on errors in the algorithm processing their file10.
Competitor risk
Algorithms can expose companies to competitive risk from the inside out. When results from machine learning models are used in the strategic decision-making process, output errors can lead executives to make poor decisions10. Whether the decision is to invest in a new project or enter a new market, algorithmic errors could lead executives down the wrong path and place the company at a competitive disadvantage.
Stagnation risk
Stagnation risk can occur if the organization’s AI adoption fails to generate any additional value for the firm. A poorly scoped integration plan will not bring all the primary stakeholders on board with the initiative. As a result, algorithmic capabilities will not be built, and meaningful value will not be created[13]. Firms that are not creating value through AI will be left behind by their more adept competitors.
Evaluation of strategic risks

A qualitative assessment of the strategic risks discussed in the previous section was conducted to determine which risks were the most significant from an organization/industry perspective. Risks were assigned an impact and probability score ranging from 1 to 3. The scores were summed to generate a severity score ranging from 1 to 6 (represented by the size of the bubble). These scores are relative and do not represent discrete values. Furthermore, the level of severity has also been represented by a colour gradient to demonstrate the generalized nature of this analysis. Some risks may be more or less severe in specific industries or organizations.
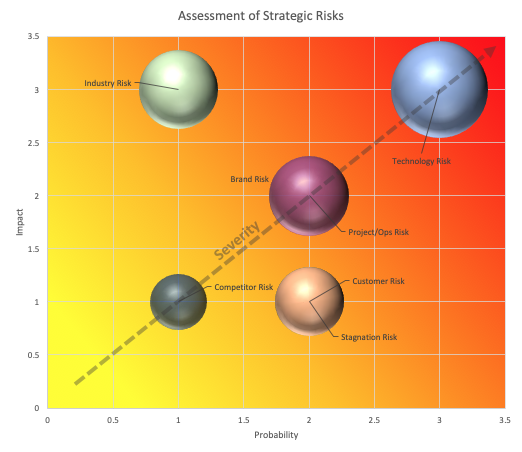
Technology risk

Technology risk scored a 3 in probability because it is currently happening, even as we speak. Malicious attempts to compromise a company’s technology are a constant threat and will only become more severe as algorithms become increasingly synonymous with business. Technology risk was given an impact of 3 because the consequence of algorithm tampering can be catastrophic. An example is when Facebook’s algorithm failed to identify fake news during the 2016 U.S. presidential election[14]. This interference was on a mass scale and most likely conducted by a state actor[15]. When these state-level cyber-attacks are directed at a company’s AI, the damages can be severe.
Industry (regulatory) risk

Changes in regulations around the use of algorithms could seriously hinder an organization if it had already invested heavily in AI. Therefore, this strategic risk receives an impact score of 3. However, the probability of this risk is relatively low. There are currently no widely accepted multi-industry regulations for ML, including data collection and design14. While some attempts have been made in Europe, the lack of clarity around this initiative suggests that any type of broad regulation may be years away14.
Brand risk

Damage to a company’s brand due to algorithmic risk has occurred in recent memory (Uber example), which is the reasoning behind a probability of 2. The impacts of this risk are hard to quantify as reputation is an intangible asset. Therefore, the impact from the risk has been deemed moderate, or 2.
Project/operational risk

This risk varies across industries, as some rely on algorithms more than others to perform core operational tasks. The probability of this occurring is thus also dependent on machine learning’s pervasiveness within the industry. An average impact score and probability of 2 were assigned to this strategic risk.
Customer risk

Many companies are currently targeting customers for marketing and sales using AI14. While potential biases in algorithms may lead to unfair segregation of demographics, customers may not know this is occurring, which gives organizations time to respond. The impact is consequently low. The increasing use of algorithms in sales and marketing increases this risk slightly with a probability of 2.
Stagnation risk

Poor adoption of machine learning models may not directly hurt an organization but will not add any significant value. There is evidence that some firms are finding it difficult to generate meaningful gains with this technology[16]. Therefore a probability of stagnation was assigned a score of 2.
Competitor risk

If algorithms are used in tandem with multiple sources of information when making strategic decisions, the risk of being misguided by AI is low. The impact and probability of losing out to competitors specifically because of algorithms is small.
Mitigation strategies
Risk appetite
Before mitigating algorithmic risks, the company must determine its appetite for risk. Setting the algorithmic risk appetite will guide what type of applications this technology is used for within the organization. Performing a risk assessment to determine the potential negative impact ML can have on the business is one way to determine the firm’s risk appetite. Algorithms can have a wide range of uses, so defining a spectrum of applications based on their unique risk can be useful. For example, algorithmic applications that fall under low severity, such as advertising to a potential customer, can be readily adopted to increase automation and improve efficiency. ML applications with a higher risk, such as lending credit, will require a more in-depth analysis to examine the risk-reward trade-off of implementing the technology. These smaller, lower severity applications are essential to roll out now to build the company’s risk appetite for larger, higher return algorithm-based projects. A 2019 survey conducted by MIT Sloan reported that 50% of companies who invest in higher-risk AI initiatives had seen value added to date, while only 23% of companies who invest in low-risk applications had seen a benefit16. Thus, it is vital for organizations to build their capacity for higher risk ML projects quickly to achieve stronger returns.
Validating machine learning models
Once the organization’s risk appetite has been defined, it should implement techniques to mitigate these algorithmic risks. McKinsey has adapted its existing model-validation framework to address algorithmic risk for its clients (Figure 2)[17] This risk management framework was designed in accordance with SR11-7 regulations specific to the banking industry, but it can be applied to any organization that relies on machine learning models17.
The framework looks at eight dimensions with 25 validators and can act as a checklist for assessing the underlying factors discussed in Figure 117. McKinsey has modified several of the items in the framework for machine learning models and has added six new elements17. These new points will require the organization to implement new policies and governance procedures17. The validators in each dimension should ensure that the project is in line with these new policies17. The following discusses some of the new validators in this framework that address the underlying factors of algorithmic risk.

Figure 2: Model validation framework. (Source: McKinsey, 2019)
Input data
The specific features of a data set can impact the predictive abilities of an ML model[18]. Feature engineering can help eliminate the technical flaws of a data set and improve the inputs of an algorithm18. Organizations will have to decide the degree of feature engineering necessary for each algorithm[19]. The level of engineering may depend on the algorithm’s application. For example, this process may not need to be as stringent if its intended use has a relatively low risk19. Higher risk applications will require closer scrutiny before implementation.
Algorithm design
Making design decisions before training the model can help mitigate many technical issues[20]. When designing algorithms, the parameters that define specific characteristics of a model, such as the number of layers in a neural network, must be defined before training can begin19. Said another way, these parameters are not part of the data set and must be chosen by the developer. These hyperparameters should be tightly regulated by the company’s risk management policies to match current industry best practices19.
Output design
Interpretability and trust in the output of models can be improved in several ways, according to McKinsey19. For linear-regression models, linear coefficients can help determine what variables an algorithm’s results depend on19. For non-linear ML models, including deep-learning techniques, methods such as Shapley values can help decision-makers determine if the outputs are reasonable19.
Model biases can be tested for using “challenger models,” which are algorithms that use alternative techniques to achieve the same goal19. This method of testing can be used to benchmark the fairness of the algorithms19. The validators will guide which tests are to be used and ensure that the models are in harmony with the organization’s policies19.
Conclusion
Algorithms are becoming more powerful and are increasingly able to complete tasks on a scale that was never before possible. As previously discussed, higher-risk investments in this field are proven to yield greater returns. Organizations need to build machine learning capabilities quickly to take advantage of this new technology. However, as businesses rush to adopt these new techniques, they must develop appropriate policies and procedures to manage the risks that accompany algorithms. The biggest strategic risks identified in this report include technology risk, industry risk, brand risk, and project risk. Adopting McKinsey’s framework to guide the input, design, and output dimensions of model building can help organizations mitigate these risks.
[1] Schatsky, D., Muraskin, C., & Gurumurthy. R. (2014, November 4). Demystifying artificial intelligence. Deloitte University Press.
[2] Schatsky, D. (2016, April 16). Machine learning is going mobile. Deloitte University Press.
[3] Deloitte. (2017). Managing algorithmic risks. Safeguarding the use of complex algorithms and machine learning. Deloitte Development LLC.
[4] McCausland, P. (2019, November 9). Self-driving Uber car that hit and killed woman did not recognize that pedestrians jaywalk. CNBC News. https://www.nbcnews.com/tech/tech-news/self-driving-uber-car-hit-killed-woman-did-not-recognize-n1079281#:~:text=Self%2Ddriving%20Uber%20car%20that%20hit%20and%20killed%20woman%20did,%2C%22%20an%20NTSB%20report%20said.
[5] Babel, B., Buehler, K. Pivonka, A., Richardson, B., & Waldron, D. (2019, February). Derisking machine learning and artificial intelligence. McKinsey & Company.
[6] Babel, B., Buehler, K., Pivonka, A., Richardson, B., & Waldron, D. (2019, February). Derisking machine learning and artificial intelligence. McKinsey & Company.
[7] Deloitte. (2017). Managing algorithmic risks. Safeguarding the use of complex algorithms and machine learning. Deloitte Development LLC.
[8] Ransbothman, S., Khodabandeh, S., Fehling, R., LaFountain, B., & Kiron, D. (2019, October). Winning with AI. MIT Sloan Management Review.
[9] Cooper, T. (2020). Business 9034 – Spring 2020 – Lecture 2.
[10] Deloitte. (2017). Managing algorithmic risks. Safeguarding the use of complex algorithms and machine learning. Deloitte Development LLC.
[11] Radinsky, K. (2016, January 5). Your algorithms are not safe from hackers. Harvard Business Review. https://hbr.org/2016/01/your-algorithms-are-not-safe-from-hackers
[12] Babel, B., Buehler, K., Pivonka, A., Richardson, B., & Waldron, D. (2019, February). Derisking machine learning and artificial intelligence. McKinsey & Company.
[13] Ransbothman, S., Khodabandeh, S., Fehling, R., LaFountain, B., & Kiron, D. (2019, October). Winning with AI. MIT Sloan Management Review.
[14] Deloitte. (2017). Managing algorithmic risks. Safeguarding the use of complex algorithms and machine learning. Deloitte Development LLC.
[15] Abrams, A. (2019, April 18). Here’s what we know so far about Russia’s 2016 Meddling. Time Magazine. https://time.com/5565991/russia-influence-2016-election/
[16] Ransbothman, S., Khodabandeh, S., Fehling, R., LaFountain, B., & Kiron, D. (2019, October). Winning with AI. MIT Sloan Management Review.
[17] Babel, B., Buehler, K., Pivonka, A., Richardson, B., & Waldron, D. (2019, February). Derisking machine learning and artificial intelligence. McKinsey & Company.
[18] Rencberoglu, E. (2019, April 1). Fundamental techniques of feature engineering for machine learning. Towards data science. https://towardsdatascience.com/feature-engineering-for-machine-learning-3a5e293a5114
[19] Babel, B., Buehler, K. Pivonka, A., Richardson, B. & Waldron, D. (2019, February). Derisking machine learning and artificial intelligence. McKinsey & Company.
[20] Deloitte. (2017). Managing algorithmic risks. Safeguarding the use of complex algorithms and machine learning. Deloitte Development LLC.
